
Tune Queries by Using Indexers – Troubleshoot Data Storage Processing-1
Azure Monitoring Overview, Handle Skew in Data, Microsoft DP-203Indexes reduce query times by creating pointers to the location where data is stored in the database. Figure 10.6 illustrates how an index on a column named EF_ID is referenced and used by the SQL query to retrieve all the columns for the matching row from the FactREADING table.
Had the query been run directly against the table instead of the index, the entire table would be scanned, looking for the matching row identified by the contents of the WHERE clause. Consider that the search for the requested row begins from the first row in the table and proceeds downward until a match is made. It would have taken six rows before the match were made. This example shows only eight rows, but imagine if there were 1 billion rows. Imagine again that the row requested by the query is located in the last row. That query would take a lot of time to run. As covered in previous chapters, three types of indexes are available for a dedicated SQL pool: clustered columnstore, clustered/nonclustered, and heap. As a refresher, Table 10.3 summarizes these indexes.
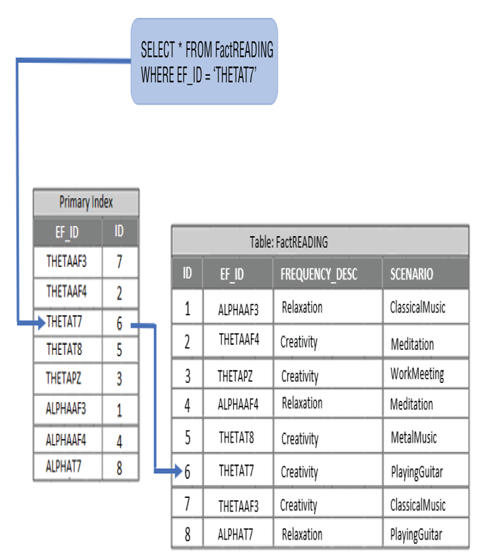
FIGURE 10.6 Tuning queries by using indexer’s indexes
TABLE 10.3 Dedicated SQL pool indexes
| Type | Benefit |
| Clustered columnstore | This offers the highest level of data compression and fastest read operations. |
| Clustered/nonclustered | This is optimal when you are selecting a single row or a few rows using a lookup or filter. |
| Heap | Inserted data is not stored in order. This is used for very large staging tables that must insert quickly. |
An important step to tuning your queries is to ensure that the queries you are running have the appropriate type of index. It basically comes down to knowing what the query does and then matching it to one of the three indexes in Table 10.3. In most big data scenarios with very large datasets, the index of choice is a clustered columnstore, which is the default when no index is provided when the table is created. However, performance is not gained from the columnstore index, because of the structure shown in Figure 10.6. Instead, the gain comes from the way the data is stored. Logically, columnstore data is structured as a table that contains rows and columns, but the data is physically stored in a column format. The structure of the physical manner in which the data is stored to disk is how performance gain is achieved from a clustered columnstore index. The type of index that applies to the illustration in Figure 10.6 has to do with clustered and nonclustered indexes. It is very often the case that you use a clustered index even when you are retrieving large datasets of up to 100 million rows. The point here is that when you need to query a lot of data, you will have better performance when using a columnstore index. Specifically, what is meant by “a lot” can be determined by remembering the law of 60 and noting that the threshold number of “a lot” is at least 60 million rows. If and when you decide to use a clustered index, consider the following SQL command, which creates one: CREATE TABLE [dbo].[READING] ([READING_ID] INT NOT NULLIDENTITY(1,1),
[SESSION_ID] INT NOT NULL,
[ELECTRODE_ID] INT NOT NULL,
[FREQUENCY_ID] INT NOT NULL,
[READING_DATETIME] DATETIME NOT NULL,
[COUNT] INT NOT NULL,
[VALUE] DECIMAL(7,3) NOT NULL)
WITH ( CLUSTERED INDEX ( READING_ID, SESSION_ID, ELECTRODE_ID, FREQUENCY_ID ));