
Optimize Pipelines for Analytical or Transactional Purposes – Troubleshoot Data Storage Processing-2
Exams of Microsoft, Microsoft DP-203This code results in the creation of an updatable columnstore index on which OLAP operations can operate. Additionally, memory will be allocated to handle OLTP transactions that get regularly ingested into the columnstore index. This has effectively separated the OLTP transactions and OLAP operations (see Figure 10.9). Keep in mind that this feature is only supported in the Business Critical or Hyperscale tiers of Azure SQL; it is not available in General Purpose.
If you experience unexpected behaviors when using HTAP on Azure SQL, there is a DMV that might lead your investigations in the right direction. The sys.dm_db_xtp_nonclustered_index_stats DMV is used to identify statistics on the in‐memory nonclustered columnstore index. As mentioned, it is also possible to implement HTAP on an Azure Cosmos DB. From an Azure Cosmos DB perspective, you implement HTAP when you provision the container, which you did in Exercise 2.2.
Turning on the analytical store resulted in something identical to that shown in Figure 10.9. Specifically, it resulted in the container containing both a transactional store and an analytical store, where data is inserted into the transactional store and auto syncs into the analytical store, also in near real time. Implementing HTAP, which separates your transactional data from the analytical one, is the most impactful action you can take to improve performance in this context.
The other option is to copy the data from the transactional table to a table that is used for analytical purposes. You can certainly imagine the complexities surrounding that, especially if there are hundreds of millions of rows. It is an option, however, if you only copy changes or delta from the source table to the destination. This was covered in the “Design for Incremental Loading” section in Chapter 3.
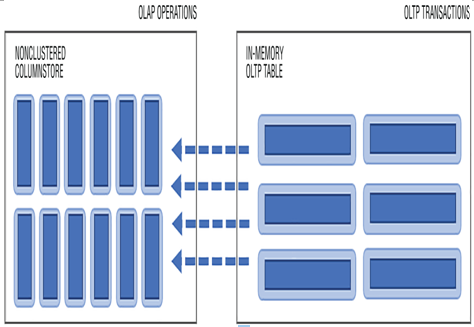
FIGURE 10.9 Optimizing pipelines for analytics or transactional purposes
The remainder of this section discusses latency discovery and performance tuning in the context of DMVs, scaling, data flows, and some Spark specifics. From a DMV perspective, the focus here is on transactions, which are OLTP transactions. The relevant DMVs that concern transactions are summarized in Table 10.6, two of which are discussed in more detail, beginning with sys.dm_pdw_nodes_tran_database_transactions.
Transactions typically comply with the ACID concept, which was introduced and discussed in Chapter 3. One aspect of the ACID concept is a mechanism called atomicity. This mechanism ensures that a transaction is successfully completed; if not, the transaction is rolled back.
A rollback is an impactful event, and its occurrence will be visible in the form of failed queries or long execution durations. Both of those symptoms can have numerous root causes, but you can use the DMV to determine if the reason is due to transactions being rolled back.
The following is a sample query that will identify if rollbacks are happening. The output of the query follows. The column value for rollback is 0, implying there are no rollbacks. A value of 1, however, would mean rollbacks are taking place.
SELECTSUM(CASE WHEN t.database_transaction_next_undo_lsn IS NOT NULLTHEN 1 ELSE 0 END) AS [rollback], t.pdw_node_id,nod.[type]
FROM sys.dm_pdw_nodes_tran_database_transactions t
JOIN sys.dm_pdw_nodes nod ON t.pdw_node_id = nod.pdw_node_id
GROUP BY t.pdw_node_id, nod.[type]
+———-+————-+———+
| rollback | pdw_node_id | type |
+———-+————-+———+
| 0 | 19 | COMPUTE |
| 0 | 19 | CONTROL |
+———-+————-+———+