
Handle Data Spill – Troubleshoot Data Storage Processing
Azure Monitoring Overview, Develop a Batch Processing Solution, Exams of Microsoft, Microsoft DP-203, Tune Queries by Using CacheA data spill is the same as a data leak, which happens when protected data is transferred to an unauthorized person or stored in an unauthorized location. Data can be spilled by copying a protected file to a publicly accessible server or by mistakenly sending an email that contains confidential information to an unnecessarily wide email audience. A data spill is different from a data breach because there is no malice or malicious intent pertaining to a data spill. In this case, the response and the approach for handling a data spill would be different from that for a data breach. A significant difference between a spill and breach is the impact. The impact does depend heavily on the kind of information that was inadvertently shared with an unauthorized party, but once the event is discovered, retrieving the mishandled information is more likely. Whether the data spill was willful, inadvertent, or due to negligence, actions must be taken to handle the spill and to prevent future incidents.
Once a data spill has been detected, it is important to notify your security team, as they should have existing procedures to manage such events. From a forensics perspective, it is important that the person or procedure that discovers the spill takes no action to resolve it. The first step is to simply report the spill. The next step would be to contain the spill, to prevent the spread and exposure of the data to a wider audience. This can be done by disconnecting the server from the network, removing IP routing from the network for the server, or stopping any forwarding of the email that contains the spilled data. Next, the organization handling the spill should perform a damage or risk assessment based on the data content. If the data contained matters of national security, the risk of damage is much greater than a list of employee salaries. Actions to be taken after the assessment are greatly dependent on the kind of data and how widely it was spread. The last step is to clean up the data spill. Removing the file from a hard drive is not enough to consider the data removed, as it can be recovered if nothing has been written to the sectors where it was stored. Software designed for completely removing data from hard drives should be used in such cases. A reboot of the machine would also be recommended so that any remnants of the data are flushed from memory if there happened to be any stored there. Once the data is removed, the final step is to identify why the incident occurred and take the necessary corrective actions to prevent it from happening again.
Taking proactive measures to prevent data spills is preferred to a reactive approach. As you learned in Chapter 8, your data needs to be marked with sensitivity levels. Unless your data is marked with confidentiality or sensitivity levels, it is not realistic to expect that a spill is identifiable. Therefore, making sure this is implemented and enforced is the first step toward preventing data spills and securing your data. Intrusion detection, anomaly detection, and multifactor authentication (MFA) are some security controls that can protect your data from unauthorized parties. Data encryption, row and column level security, data masking, Azure Key Vault, RBAC, and ACLs, which were also covered in Chapter 8, are all options for securing your data. Finally, the staff who has access to confidential data needs to be regularly trained on how to handle and share this kind of information.
Another example of a data spill occurs in the Apache Spark context when the size of the data being processed exceeds the allocated memory for the given task. This is not an out of memory (OOM) exception but a heap memory issue, which does not leak into user or reserved memory space. Figure 10.4 illustrates a data spill in this context.
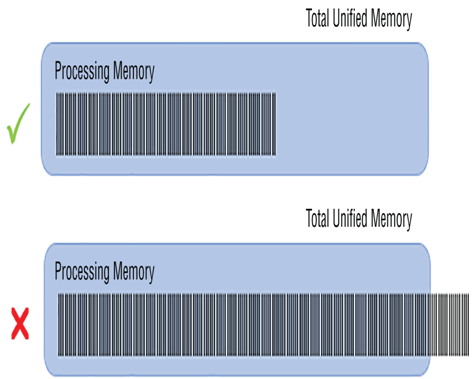
FIGURE 10.4 Handling data spill memory capacity
The impact of such a scenario is performance degradation caused by the overflowed data being written to disk. Writing to and reading data from disk is much slower than writing and reading from memory. Therefore, it is important to keep the datasets stored in partitions at a size that will fit into the task process, which hovers around a 4 GB limit. You can see the amount of data spill for a given job task by selecting the View Details link for the given task (refer to Figure 9.26). The Spill (Memory) and Spill (Disk) metrics represent the amount of data that exceeds the allocated memory. If values exist for these headings, your job partition is suffering from data spill.
Data skewing is one of the most common causes for data spills. If you determine there is significant skewing, fix that issue by either repartitioning to reduce the amount of data per partition or reshuffling the data. The intention behind reshuffling the data on a partition is to reduce its size so that it fits within the allocated memory. Another option is to increase the worker node size so that more memory is available for the task to perform its operation.